- Title: Exploring Architectures for Cryptographic Access Control Enforcement in the Cloud for Fun and Optimization
- Authors: Stefano Berlato, Roberto Carbone, Adam J. Lee, Silvio Ranise
- DOI: 10.1145/3320269.3384767
Abstract
To facilitate the adoption of cloud by organizations, Cryptographic Access Control (CAC) is the obvious solution to control data sharing among users while preventing partially trusted Cloud Service Providers (CSP) to access sensitive data. Indeed, several CAC schemes have been proposed in the literature. Despite their differences, available solutions are based on a common set of entities—e.g., a data storage service or a proxy mediating the access of users to encrypted data—that operate in different (security) domains—e.g., on-premise or the CSP. However, the majority of the CAC schemes assumes a fixed assignment of entities to domains; this has security and usability implications that are not made explicit and can make inappropriate the use of a CAC scheme in certain scenarios with specific requirements. For instance, assuming that the proxy runs at the premises of the organization avoids the vendor lock-in effect but may substantially mine scalability. To the best of our knowledge, no previous work considers how to select the best possible architecture (i.e., the assignment of entities to domains) to deploy a CAC scheme for the requirements of a given scenario. In this paper, we propose a methodology to assist administrators to explore different architectures of CAC schemes for a given scenario. We do this by identifying the possible architectures underlying the CAC schemes available in the literature and formalize them in simple set theory. This allows us to reduce the problem of selecting the most suitable architecture satisfying a heterogeneous set of requirements arising from the considered scenario to a Multi-Objective Optimization Problem (MOOP) for which state-of-the-art solvers can be invoked. Finally, we show how the capability of solving the MOOP can be used to build a prototype tool assisting administrators to preliminary perform a ``What-if'' analysis to explore the trade-offs among the various architectures and then use available standards and tools (such as TOSCA and Cloudify) for automated deployment in multiple CSPs.Complementary Material
Below, you find links to complementary material and additional resources referenced in the paper.
Cloudify Blueprint
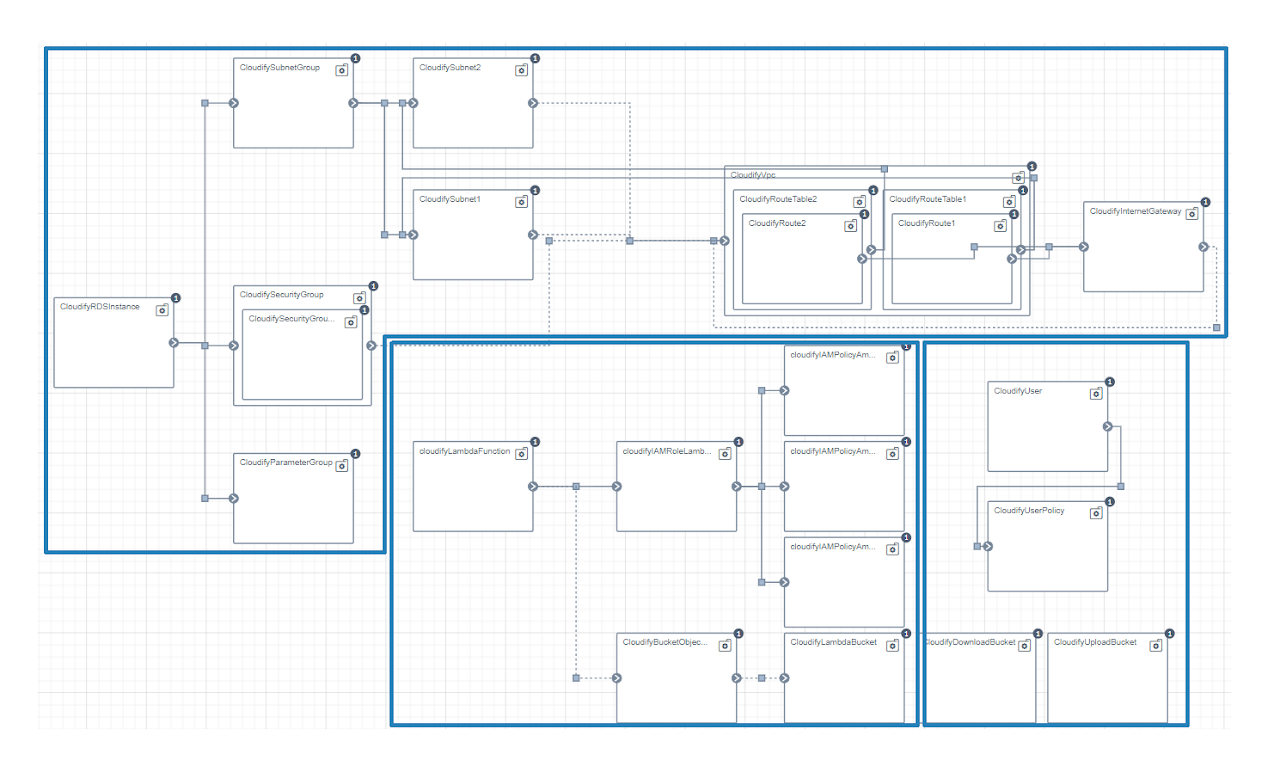
We present the Cloudify blueprint we developed for an architecture that we later deployed for the eGovernment scenario. The source code of the Cloudify Blueprint is available here.
Each white rectangle is a node and it represents a cloud service (e.g., security groups, cloud functions). Links are relationships between nodes and are used to control the deployment flow. The blueprint contains three main clusters (blue borders). The cluster on top models the relational database service (i.e., MS, a Relational Database Service in AWS) while the cluster in the middle models the cloud function (i.e., RM, a Lambda function in AWS). The last cluster on the bottom-right corner models the storage service (i.e., DS, a S3 service in AWS). The proxy runs in the users’ computers. Therefore, the proxy is not part of the blueprint.
Fully Working Prototype
We developed a fully working prototype (please see the repository) implementing the cryptographic access control scheme developed by Garrison et al. The prototype was tested with several simulated sequences of operations combining the creation of users and roles, assignment and revoking of permissions and the creation, update and management of files. The prototype offers a user interface based on web technologies and RESTful APIs.
Web Dashboard
We implemented a proof-of-concept application of our architectural model and the Multi-Objective Optimization Problem (MOOP) in a web dashboard (please see the repository). For demonstration purposes, the MOOP is reduced to a constrained weighted sum optimization problem. The dashboard allows configuring pre-filters on the possible architectures, weights and soft-hard constraints. The optimization problem is solved in real-time and the resulting architectures, along with the effect on the security and usability goals, are shown in the last blue sections. You can freely interact with the dashboard.



